
[알고리즘] 이진탐색과 정렬의 시간복잡도
👩💻 이진 탐색이란?
이진 탐색이란, 정렬된 배열에서 특정한 값을 찾아내는 알고리즘이다. 왼쪽과 오른쪽에 각각 파티션을 두어, 범위의 중간 값과 찾고자 하는 값을 비교하여 범위를 절반 씩 좁혀나간다.
이처럼 범위를 반으로 줄여가며 탐색을 반복하므로 속도가 빠른 편이다. 시간 복잡도는 O(logN)이다.
"답이 x이상일 수 있는가?" 답이 x이상이 아니다 -> 답이 x보다 작은 범위를 탐색 답이 x이상이다 -> 답이 x이상인 범위를 탐색 이런 경우 문제를 이진탐색으로 접근할 수 있다.
각 sorting의 시간 복잡도를 비교해 보자!
| 이름 | 평균 | 최악 | 안정성 |
|---|---|---|---|
| 버블 정렬 | n2 | n2 | true |
| 선택 정렬 | n2 | n2 | false |
| 삽입 정렬 | n2 | n2 | true |
| 퀵 정렬 | nlog(n) | n2 | false |
| 힙 정렬 | nlog(n) | nlog(n) | false |
| 병합 정렬 | nlog(n) | nlog(n) | true |
❕ algorithm 의 sort는 퀵 정렬을 기반으로 구현된 함수이다.
코드를 살펴보며 동작 방법을 분석해 보자.
vector<int> v;
int binarySearch(int len, int x) {
int lo = 0;
int hi = len - 1;
int mid = 0;
while (lo <= hi) {
mid = (lo + hi) / 2;
if (v[mid] == x) {
return 1;
}
else if (v[mid] > x) {
hi = mid - 1;
}
else {
lo = mid + 1;
}
}
return 0;
}
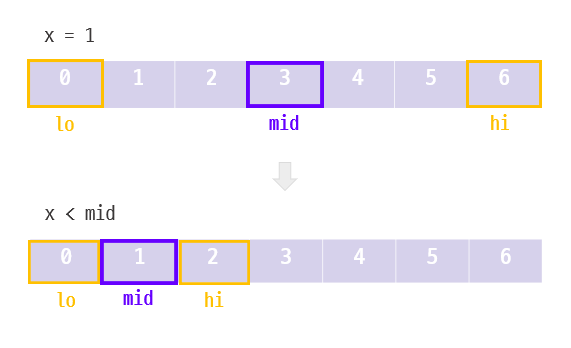
배열 v의 길이를 len이라 하고, x는 찾고자 하는 데이터의 값이다. 먼저, 왼쪽과 오른쪽의 범위를 구분지어 줄 변수인 lo와 hi를 초기화한다.
맨 처음 시작은 배열의 전 범위를 포함해야 하므로, lo는 0, hi는 배열의 마지막 원소를 가르키도록 한다.
이후 왼쪽 파티션 lo가 오른쪽 파티션 hi보다 커지기 전까지, 범위의 중앙값 mid와 x를 비교하고 둘의 값이 같으면 반복문을 탈출한다.
만약 mid가 x보다 크면 x는 중앙에서부터 왼쪽에 존재한다는 의미이므로 hi를 중앙값보다 하나 작은 값으로 바꿔준다. mid가 x보다 작다면, x는 mid값으로부터 오른쪽에 존재한다는 뜻이므로 lo를 mid보다 하나 큰 값으로 바꾼다.
이런 방법으로 범위를 반 씩 좁혀 나가며 찾고자 하는 데이터를 탐색한다.
# 카테고리
- BOJ 36
- Algorithm 12
- CodingTest 11
- Web 9
- Javascript 8
- Vue 7
- React 7
- DBProject 4
- Python 3
- Tech-interview 3
- Express 3
- Next 3
- Github 2
- Django 2
- C 1
- C++ 1
- WebGame 1